A Harness Framework for Embodied Manipulation
 Guava: Effective and Universal Harness for Embodied Manipulation
Guava: Effective and Universal Harness for Embodied Manipulation
* Equal contribution
Overview
We present Guava, a harness framework for embodied tool use. Through systematic exploration of the design space, we identify three key ingredients of an effective harness: iterative perception–reasoning–action loops, semantic action abstractions, and multimodal observations. Using this harness, we distill embodied manipulation into a 4B open-source model with fewer than 2K simulation trajectories — matching frontier proprietary models in both simulation and the real world, with strong zero-shot generalization to unseen objects, novel instructions, and long-horizon tasks.
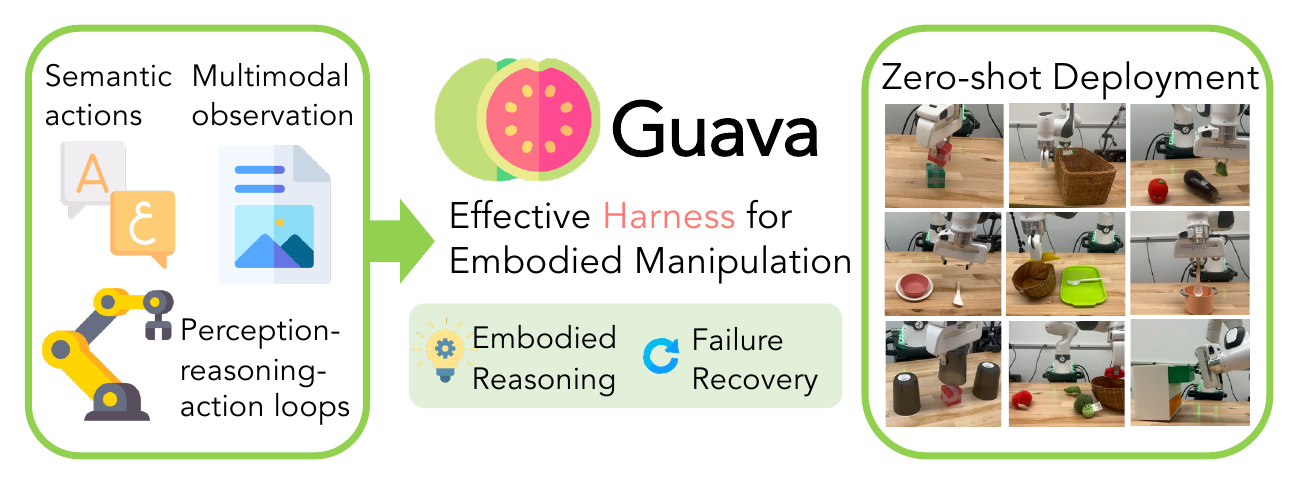
Ingredients for an effective harness
Existing harness systems often rely on one-shot code generation, domain-specific pipelines coupled with powerful frontier models, which makes robust long-horizon behavior and failure recovery expensive and brittle. By exploring the design space of agent workflows, action spaces, and observation spaces, we reframe the design problem around three reusable ingredients that consistently matter for embodied manipulation:
-
Iterative perception–reasoning–action loops
ReAct-style loops let the agent adapt to execution outcomes and recover from failures, rather than committing to a single open-loop plan.
-
Semantic action abstractions
Tools that encapsulate manipulation skills at a semantic level free the language model to focus on task decomposition and planning instead of low-level control.
-
Multimodal observations
Rich visual and structured observations provide the environmental context that embodied reasoning requires.
Guava-Agent-4B
Building on these principles, we ask whether an effective harness can serve as a universal interface for embodied manipulation across model scales — including small open-source ones. We distill embodied tool-use behaviors into a small open-source model (Qwen3.5-4B), using fewer than 2K trajectories collected entirely in simulation and perform supervised fine-tuning.
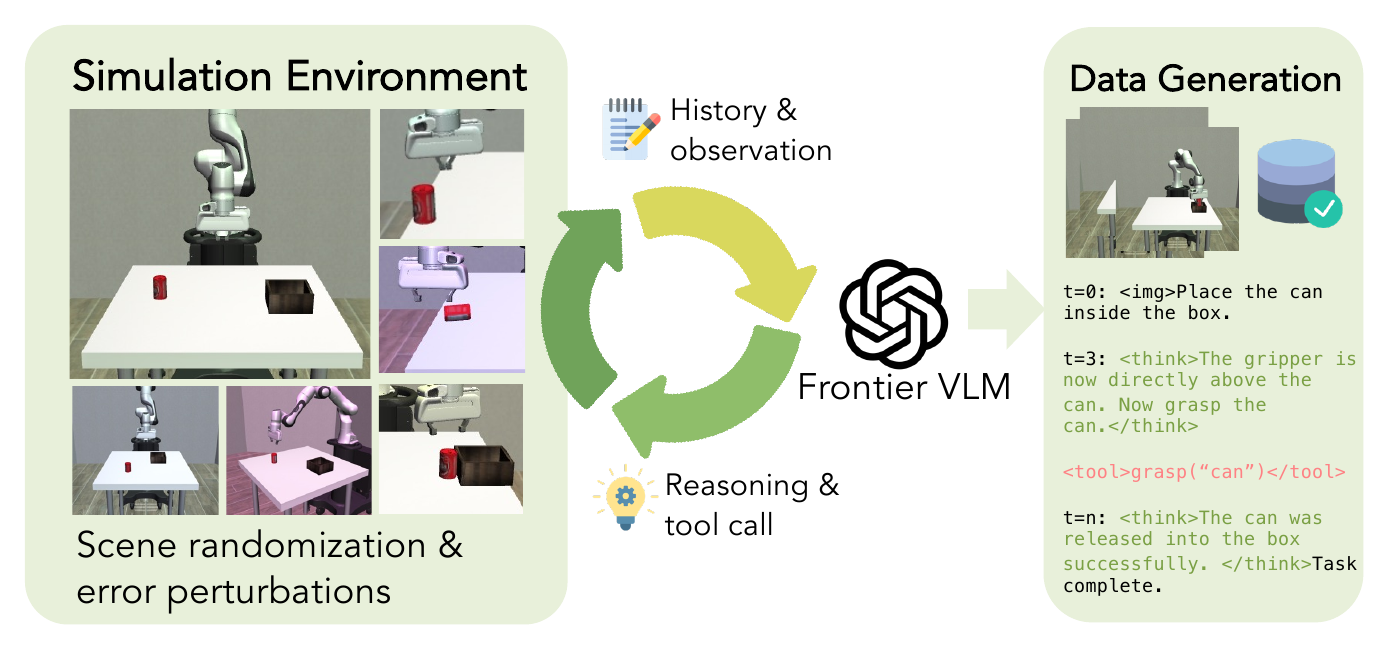
Data gallery
Results
Guava-Agent-4B achieves the highest overall zero-shot real-world success rates on both in-distribution (86%) and out-of-distribution (92%) tasks, outperforming all baselines.
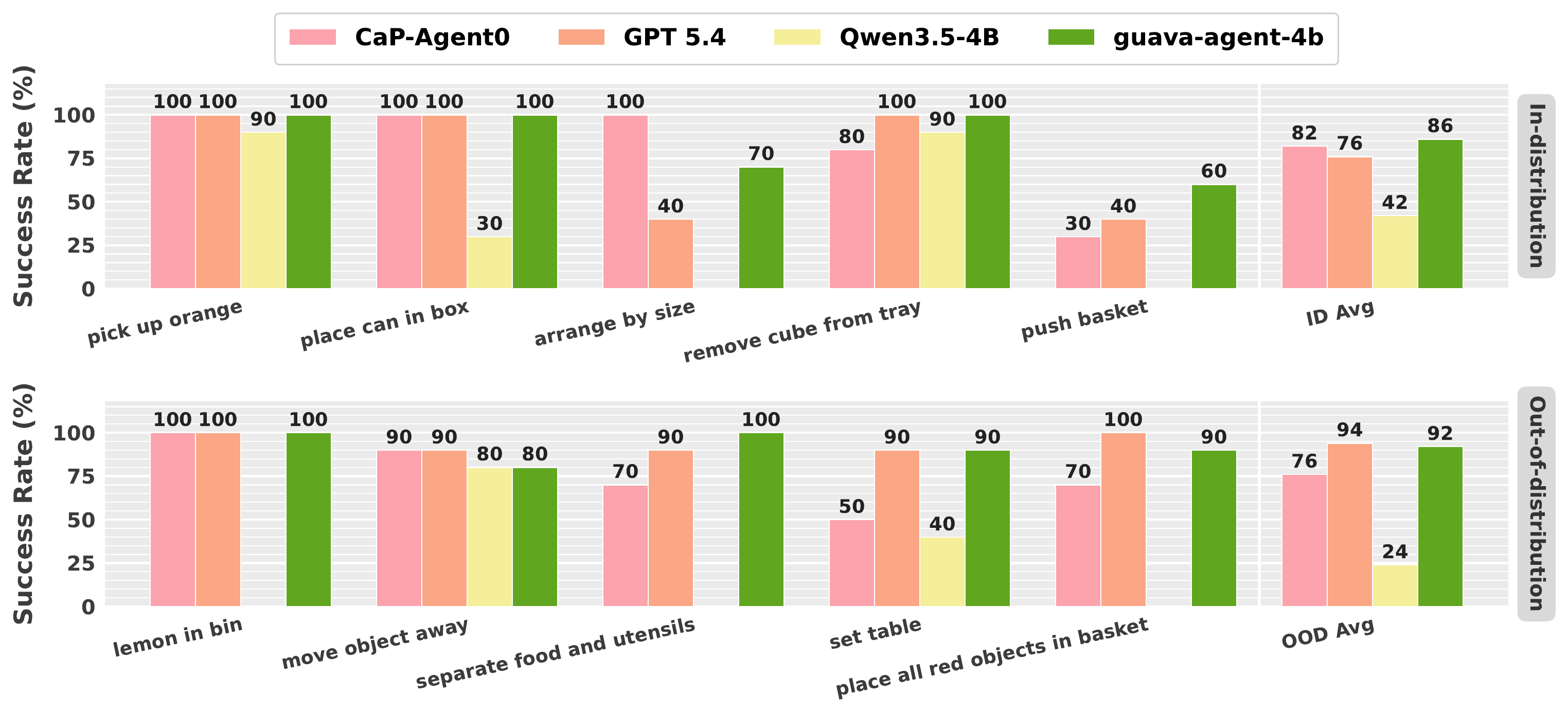
Our method generalizes zero-shot across a broad range of tasks that requires semantic and geometric reasoning. It is able to handle long-horizon tasks, and is robust to distractors, OOD tasks and setups.
Failure recovery
Guava interleaves observation, reasoning, and tool execution on every step — so when something goes wrong, the agent can see and revise the plan. We observe successful recovery from previously unseen failures, as recovery emerges from reasoning over execution feedback beyond memorizing predefined correction patterns.
RL fine-tuning
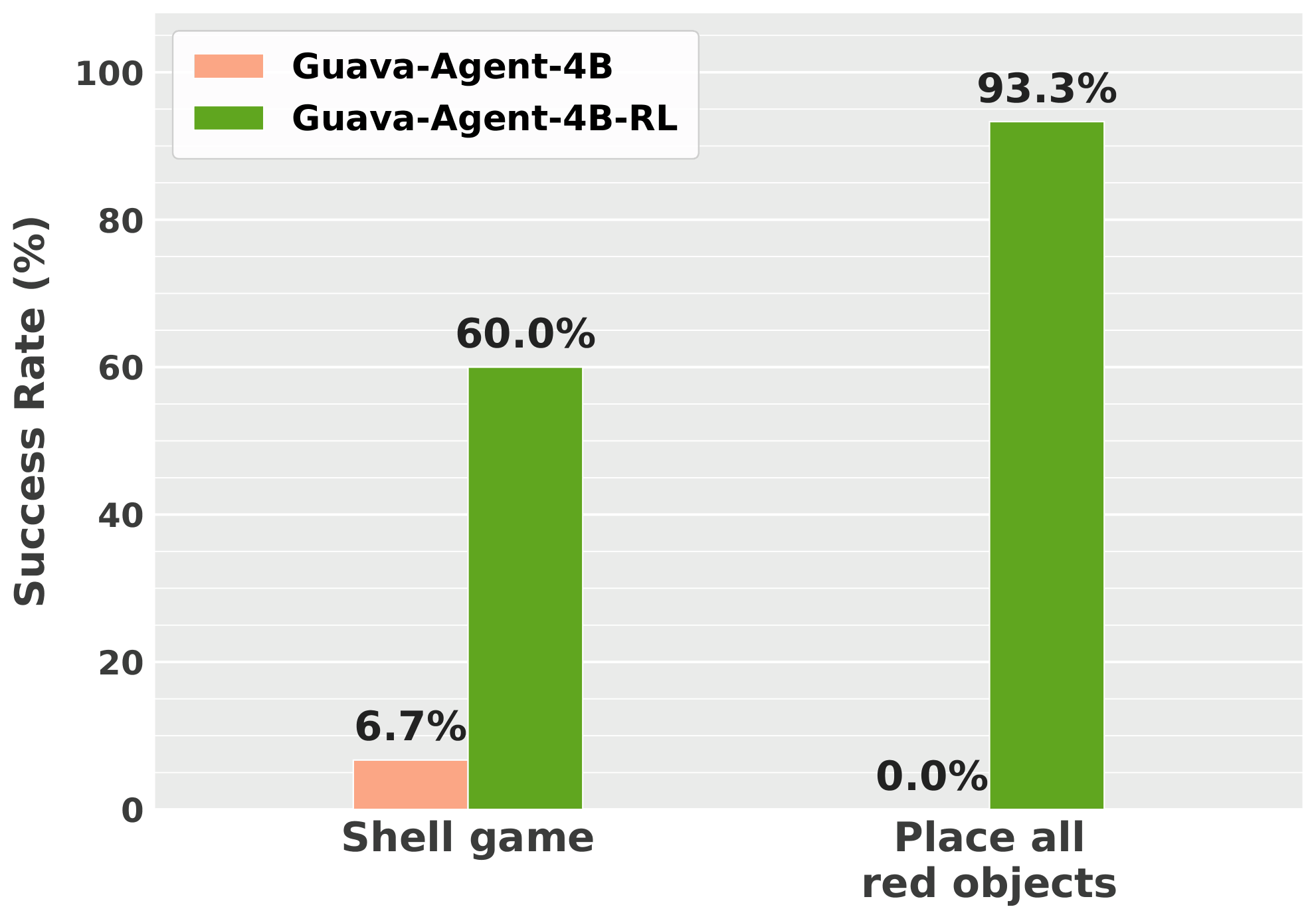
We further finetune Guava-Agent-4B with GRPO on the two challenging, OOD long-horizon manipulation tasks that require substantially more multi-step reasoning, error recovery, and action planning. While the SFT policy struggles on both shell game (6.7%) and place all red objects in basket (0.0%), RL fine-tuning improves performance to 60.0% and 93.3%, respectively. The large gains suggest that training on challenging long-horizon tasks with sparse success rewards effectively strengthens recovery behaviors and enables the policy to better handle off-trajectory states.
BibTeX
@misc{liu2026guavaeffectiveuniversalharness,
title={Guava: An Effective and Universal Harness for Embodied Manipulation},
author={Haowen Liu and Xirui Li and Shaoxiong Yao and Peng Shi and Tianyi Zhou and Jia-Bin Huang and Furong Huang and Jiayuan Mao},
year={2026},
eprint={2606.18363},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2606.18363},
}